Искусственный интеллект: Глубокое обучение
На сегодняшний день развитие Artificial intelligence (AI) является одним из важнейших направлений в России, к которому приковано внимание не только инженеров отрасли, но и правительства.
Проверка концепции AI
Проблематика
Возможно ли на основе имеющихся данных построить предсказательную модель или можно ли в принципе собрать данные требуемые для целевой модели?
Действительно ли для решаемой задачи нужно применять методы глубокого обучения, или можно обойтись менее затратными вычислительными методами, такими как линейные модели, машинное обучение и т.д.?
Исследование
Анализ данных и выявление значимых паттернов, особенно в условиях, когда данные не имеют заранее заданную структуру, - это творческий процесс, требующий компетенций в работе с данными и алгоритмами, а также удобного инструментария и накопленной большой библиотеки методов и алгоритмов для быстрой проверки идей. Также требуется опыт управления временем исследования, поскольку все возможные комбинации перебрать невозможно, а ошибки в выборе исследуемых гипотез стоят дорого: много трудозатрат, вычислительных ресурсов, упущенные возможности и время. При рассмотрении конкретных задач мы отсекаем некоторые гипотезы экспертно, некоторые гипотезы исследуем частично в ограниченное время, а часть глубже. В зависимости от достижения некоторого порога значимости влияния данных на переменную отклика мы делаем заключение о возможной эффективности тех или иных методов искуственного интеллекта (ИИ).
Результат
Реалистичный план ИИ проекта или техническое задание, в которое входят:
- организационная схема решения задачи (по возможности - прототип в MATLAB)
- обоснованные требования к качеству и количеству данных, их достаточности
- оптимальная методика сбора и предобработки данных (в некоторых случаях - приложение автоматизирующее сбор и разметку данных)
- выбранные архитектуры нейронных сетей или более простых алгоритмов
- схема развертывания или портирования алгоритмов, соответствующая выбранным сетям (например, развертывание на корпоративном сервере, на мобильном телефоне, встроенных платформах основанных на GPU, FPGA, MCU, CPU)
- рекомендации по обучению и дообучению систем.
- Deep Learning Toolbox
- Statistics and Machine Learning Toolbox
- Parallel Computing Toolbox
- Text Analytics Toolbox
- Predictive Maintenance Toolbox
- Audio Toolbox
- Database Toolbox
- Image Processing Toolbox
- Computer Vision Toolbox
- Signal Processing Toolbox
- Wavelet Toolbox
- Fuzzy Logic Toolbox
- System Identification Toolbox
- OPC Toolbox
- Data Acquisition Toolbox
- Image Acquisition Toolbox
- MATLAB для профессионалов (MLBE)
- Обработка и визуализации данных в MATLAB (MLVI)
- Машинное обучение в MATLAB (MLML)
- Глубокое обучение в MATLAB (MLDL)
- Статистический анализ в MATLAB (MLST)
- Обработка изображений в MATLAB (MLIP)
- Разработка систем компьютерного зрения в MATLAB (MLCV)
- Обработка сигналов в MATLAB (MLSG)
- Предобработка и извлечение свойств сигнала с MATLAB (MLSP)
Предобработка данных
Для задач глубокого обучения наличие качественной базы данных является ключевым атрибутом успешного решения задачи. Образно говоря, качественная и репрезентативная выборка данных - это 90% успеха.
Критерии качественной выборки
- Баланс. Количество элементов каждого класса примерно одинаково
- Достаточность. Элементы содержат атрибуты, которые характеризуют данные и позволяют либо разделить различные классы, либо создать предсказательную модель
Сценарии подготовки качественной выборки данных для ИИ проекта:
- Данные уже есть и их надо использовать.
- Данных пока нет и их нужно оптимальным образом собрать.
- Гибридный сценарий когда данные есть, но их нужно дополнять или улучшать.
Часто встречающиеся проблемы и методы решения:
- Данные хранятся в разных файлах, базах данных, имеют различные форматы, измерены с разной частотой, имеют пропуски и так далее.
Решение: качественная предварительная обработка, требующая высоких компетенций и инфраструктуры автоматизации этой работы для того, чтобы работа с данными не превратилась в пожизненную каторгу.
- Результат обучения на основе несбалансированных данных может привести к неудовлетворительному результату.
Решение: для качественного результата необходима либо определенная настройка алгоритма, либо дополнение или корректировка выборки, либо синтез новых данных.
- Характеристики, отвечающие за уникальность, могут либо отсутствовать, либо быть очень слабо выражены.
Решение: при отсутствии характеристик необходимо пересмотреть подход к сбору данных. При слабо выраженных характеристиках (например, много шума с амплитудой значительно превышающей полезный сигнал) необходимо увеличивать размер базы данных (собирать дополнительные данные).
- Данных нет, а собирать их кажется дорого.
Решение: мы умеем задействовать много возможностей по эффективному сбору данных, таких как быстрое прототипирование мобильного приложения, подключение к существующему промышленному оборудованию или камерам, создание приложений по автоматизации разметки данных, импорт и совмещение нескольких источников данных и так далее.
У нас есть разносторонний опыт решения типовых и нестандартных проблем с данными на любом этапе ИИ проекта. Мы не скрываем наших компетенций и готовы не только решить задачу, но и научить пользоваться нашими инструментами.
- MATLAB
- Optimization Toolbox
- Parallel Computing Toolbox
- Statistics and Machine Learning Toolbox
- Deep Learning Toolbox
- Text Analytics Toolbox
- Predictive Maintenance Toolbox
- Signal Processing Toolbox
- Audio Toolbox
- Wavelet Toolbox
- Data Acquisition Toolbox
- Instrument Control Toolbox
- Image Acquisition Toolbox
- Image Processing Toolbox
- OPC Toolbox
- MATLAB для профессионалов (MLBE)
- Обработка и визуализации данных в MATLAB (MLVI)
- Обработка сигналов в MATLAB (MLSG)
- Предобработка и извлечение свойств сигнала с MATLAB (MLSP)
- Машинное обучение в MATLAB (MLML)
- Статистический анализ в MATLAB (MLST)
- Обработка изображений в MATLAB (MLIP)
- Ускорение и распараллеливание MATLAB кода (MLAC)
- Программирование в MATLAB (MLPR)
- Глубокое обучение в MATLAB (MLDL)
Выбор рабочего прототипа
Согласно теореме о бесплатных завтраках в сфере оптимизации, не существует универсального алгоритма, способного аппроксимировать любые данные произвольного вида.
Любой новый AI проект, который не повторяет уже опубликованное решение, а ищет новое, как правило требует работы над созданием, исследованием и сравнением нескольких вариантов прототипов AI алгоритма.
Основные сложности возникают при определении емкости модели. Если емкость модели относительно большая, на выходе мы получим переобученную модель, которая будет плохо вести себя на новых данных. Другая крайность: низкая емкость модели приведет к недообучению, что тоже будет выражено в плохой предсказательной способности на новых данных.
Самый простой случай выбора модели - техника передачи обучения. В этом случае используют несколько хорошо обученных нейросетей и дообучают их на профильной выборке.
Казалось бы 90% всех AI проектов можно реализовать по такому простому шаблону, но в реальности даже при этом подходе все быстро становится очень сложным, поскольку любая известная сеть создавалась для конкретной задачи и обучалась на данных что имелись у исследователя в то время.
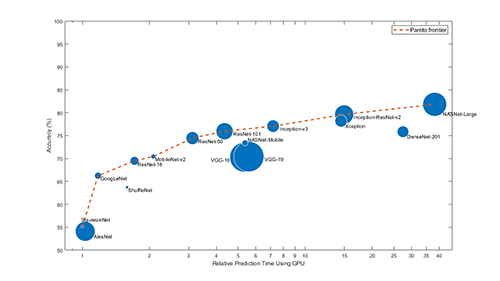
Пример вариантов архитектур для техники передачи обучения
- Проверка гипотез о конкретных реализациях алгоритма обходится очень дорого по срокам и вычислительным ресурсам. В среднем за AI проект желательно проверить не менее 100 гипотез, но по факту удается проверить не более десятка.
Решение: даже при наличии инструментов автоматизации, распараллеливания, оптимизации и вычислительных кластеров требуются навыки и опыт подобной работы в MATLAB. По нашему опыту работа с куратором AI проекта от ЦИТМ Экспонента сокращает время и вероятность ошибочных решений в разы (5-10 раз).
- Зачастую сети, имеющие хорошую предсказательную способность, не удовлетворяют иным важным характеристикам задачи, например скорости работы в реальном времени, ограничения по памяти или портируемости.
Решение: для поиска решения мы применяем множество подходов, таких как быстрое прототипирование сетей на целевых платформах с помощью автоматического синтеза платформо-зависимого кода, редактирование существующих известных сетей, создание специализированных сетей с нуля.
- При реализации алгоритмов с ограниченным набором обучающих данных очень сложно выбрать оптимальный алгоритм, поскольку конечная точность очень сильно будет зависеть от экспертных знаний.
Решение: применение методов перекрестной проверки позволяет подобрать оптимальную точность.
Другим важным компонентом успешного решения является выбор характеристик объекта и предобработки, а иногда и сжатие данных без потери ценной информации.
Мы создаем AI алгоритмы в MATLAB, потому что это дает нам значимый результат быстрее и гибче, что позволяет удешевить исследование и получение конечного продукта.
- MATLAB
- Simulink
- Parallel Computing Toolbox
- Deep Learning Toolbox
- Text Analytics Toolbox
- Statistics and Machine Learning Toolbox
- Predictive Maintenance Toolbox
- Database Toolbox
- Optimization Toolbox
- Global Optimization Toolbox
- Fuzzy Logic Toolbox
- System Identification Toolbox
- Image Processing Toolbox
- Computer Vision Toolbox
- Audio Toolbox
- Wavelet Toolbox
- Signal Processing Toolbox
Обучение алгоритма
Обучение алгоритма является самым вычислительно сложным процессом из всех представленных. Иногда обучение может занимать несколько дней для одной конфигурации, хотя и нет гарантии, что конкретная конфигурация алгоритма была наиболее эффективной.
Процесс обучения выстраивается в зависимости от типа и сложности задачи и количества имеющихся данных для обучения. Здесь нет единого и универсального шаблона. Обучение некоторых задач не требует специальных знаний и навыков, с другой стороны можно столкнуться с такими задачами, в которых обучение может вызвать серьёзные трудности даже у специалиста с большим опытом. Как пример: задачи выделения объектов на изображении с высоким разрешением, когда объекты имеют различный масштаб от нескольких пикселей до размеров, сравнимых с размером всего изображения, или задача обработки и предсказания многомерных временных последовательностей. В зависимости от исходной задачи мы можем применить различные подходы. В некоторых случаях приходится исследовать и искать новые подходы к обучению, а в некоторых достаточно применить базовые техники с параметрами обучения по умолчанию. Типичные проблемы:
- Относительно мало данных, когда сложно не только выбрать достаточно емкую модель, но и правильно ее обучить.
Решение: качественный выбор характеристик (фич), использование большого объема комбинаций алгоритмов, применение техник регуляризации.
Решение: очень часто качественная предобработка данных гораздо важнее, чем сама модель, и на предобработку необходимо больше усилий. Хорошие данные - это 90% трудозатрат и успеха AI проекта.
- Модель высокой сложности с большим количеством параметров для обучения. Ее обучение занимает много времени, вычислительных ресурсов, но в конечном итоге не достигается сходимость решения. Мы успешно решаем подобные задачи благодаря богатому опыту применения следующих подходов:
a. Настройка гиперпараметров систем
b. Улучшение качества предобработки данных
c. Добавление синтетических данных в выборки обучения
d. Экспертные знания по выбору функции ошибки под задачу
e. Разбиение задачи оптимизации на более простые подзадачи
- MATLAB
- Simulink
- Parallel Computing Toolbox
- Statistics and Machine Learning Toolbox
- Deep Learning Toolbox
- Text Analytics Toolbox
- Predictive Maintenance Toolbox
- Database Toolbox
- Optimization Toolbox
- Global Optimization Toolbox
- Fuzzy Logic Toolbox
- System Identification Toolbox
- Image Processing Toolbox
- Audio Toolbox
- Computer Vision Toolbox
- Wavelet Toolbox
- Signal Processing Toolbox
Развертывание нейронных сетей на целевых платформах
Обученная нейронная сеть должна быть перенесена на целевую платформу для решения боевых задач. Одним из существенных преимуществ модельно-ориентированного проектирования - это возможность разделить создание алгоритма и его реализацию на целевой платформе. Такое деление позволяет алгоритмисту сфокусироваться на прикладной задаче, будучи уверенным, что сложностей с реализацией на целевой платформе не будет. Рассмотрим 2 типа целевых платформ:
Сервер в инфраструктуре предприятия
Алгоритм может быть развернут на MATLAB сервере для обслуживания многих пользователей, работающих через “тонкие клиенты”. Такой подход экономит силы IT-службы по установке и поддержанию приложения. Обновления алгоритма на таком сервере может быть осуществлено “на лету” без перезагрузки программного и аппаратного обеспечения. Минусом такой реализации является необходимость передачи данных по сети на сервер, что может привести к нежелательным задержкам.
Встраиваемая платформа
Встраиваемые системы используются в тех случаях, где алгоритм должен сработать моментально на захваченных данных и передать уже результаты классификации. Архитектуры могут быть самыми разными, потому должен быть гарантирован быстрый перенос алгоритма на различные архитектуры (микропроцессоры, графические процессоры и ПЛИС). Использование модельно-ориентированного проектирования позволяет получить исходные коды для реализации на произвольной встраиваемой системе с помощью методов автоматической генерации кода.
Итого подход модельно-ориентированного проектирования позволяет упростить реализацию алгоритмов глубокого обучения на любых платформах, освобождая время разработчиков для работы над самими алгоритмами. Мы выполнили десятки проектов по развертыванию алгоритмов на различных платформах и готовы безболезненно провести вас по этому маршруту.
Выполненные проекты
В данном разделе вы можете ознакомиться с примерами наших работ, выполненных для других заказчиков, по тематике искусственного интеллекта. В рамках сотрудничества с нами возможна реализация всех описанных выше этапов, а также решение ваших специальных и специфических задач.
Доступ к актуальным технологиям и общение с передовыми заказчиками из разных отраслей позволяет нам выполнять проекты и переиспользовать накопленный уникальный опыт на самом высоком уровне. Особенностью сотрудничества с нами является передача компетенций заказчику, что в дальнейшем позволяет компании работать в данном направлении самостоятельно, не прибегая к помощи извне.