Искусственный интеллект: Анализ данных
Данные должны работать. Для этого нужно постоянно задаваться вопросом: как извлечь из них пользу? Конечно, универсальная мера здесь – это прибыль компании. Но не менее ценно в ходе анализа обрести глубокое понимание бизнес-процессов компании. Мы умеем принимать задачи на языке бизнес требований, переводить их на язык науки о данных и на этой основе осуществлять самые амбициозные планы с применением data science. Одним универсальным дата сайентистом (специалистом в data science) здесь не обойтись. Вам понадобится несколько разных ролей и компетенций. Особенно, если работа над культурой данных в компании только начинается.
В ЦИТМ Экспонента работают инженеры с богатым опытом построения процессов с применением data science и мы готовы помочь вам на каждом из этапов проектов: начиная от выбора и определения темы работы, продолжая профессиональным обучением, а также совместной их проработкой до получения эффективного результата на этапе внедрения и дальнейшего масштабирования.
Давайте обсудим, из чего состоит успешный data-science проект!
Служба анализа данных или Data-отдел?
У наук о данных огромное количество приложений в любых отраслях. Однако следует помнить, что конечная задача data-отдела любой компании всего одна: решение бизнес-проблем. Сотрудники data-отделов заняты не решением аналитических задач, а решением бизнес-задач с помощью аналитики.
Иногда этими задачами занимается не отдел, а распределенная служба (например, Офис Chief Data Scientist, CDS). Сотрудники такой службы фактически трудоустроены в разных профильных отделах, поближе к прикладной специфике. Они сочетают знание дата-аналитики, например, с компетенциями электрической инженерии, кредитного скоринга, менеджмента или маркетинга.
Службу анализа данных (в отличие от data-отдела) можно вырастить на базе уже имеющихся кадров путем организации обучения мотивированных сотрудников.
Мы предоставляем целый ряд обучающих программ по анализу данных, обеспечиваем экспертные консультации и можем взять на себя ведение проектов. Также мы готовы подробно погрузиться в бизнес-процессы вашей компании и определить вместе с вами, решение каких бизнес-задач с помощью методов Data science будет наиболее прибыльно и выгодно для вас. Это позволит сэкономить время на “тупиковых ветвях” на ранних этапах работ и сконцентрироваться на том, что действительно важно.
Бизнес-анализ
Современный бизнес – это сложный многоуровневый процесс, управление которым является непростой задачей. Анализ данных дает более глубокое понимание бизнес-процессов. Это позволяет обеспечить более длительный срок жизни изделий, высокую отказоустойчивость, эффективный расход ресурсов, и так далее. С точки зрения спроса, данные помогают не только найти и удовлетворить его, но и создать его путем рекламы и за счет открытия новых сервисов.
Каждое внедренное решение уникально. Детали реализации каждого решения зависят от многих факторов, но «опорные» этапы проекта в data science остаются одинаковыми. Они приведены в диаграмме CRISP-DM, которая удобно перекладывается на любую бизнес-логику. Согласно CRISP-DM, первый шаг на этом пути – понимание бизнес-задачи. На этом шаге происходит формализация бизнес-проблемы: ее определение на языке бизнеса и перевод на язык дата-аналитики. Целиком, диаграмма кросс-индустриального стандартизованного процесса исследования данных (CRISP-DM) состоит из целого ряда шагов (и вовлекает ряд специалистов) представленных на диаграмме ниже.
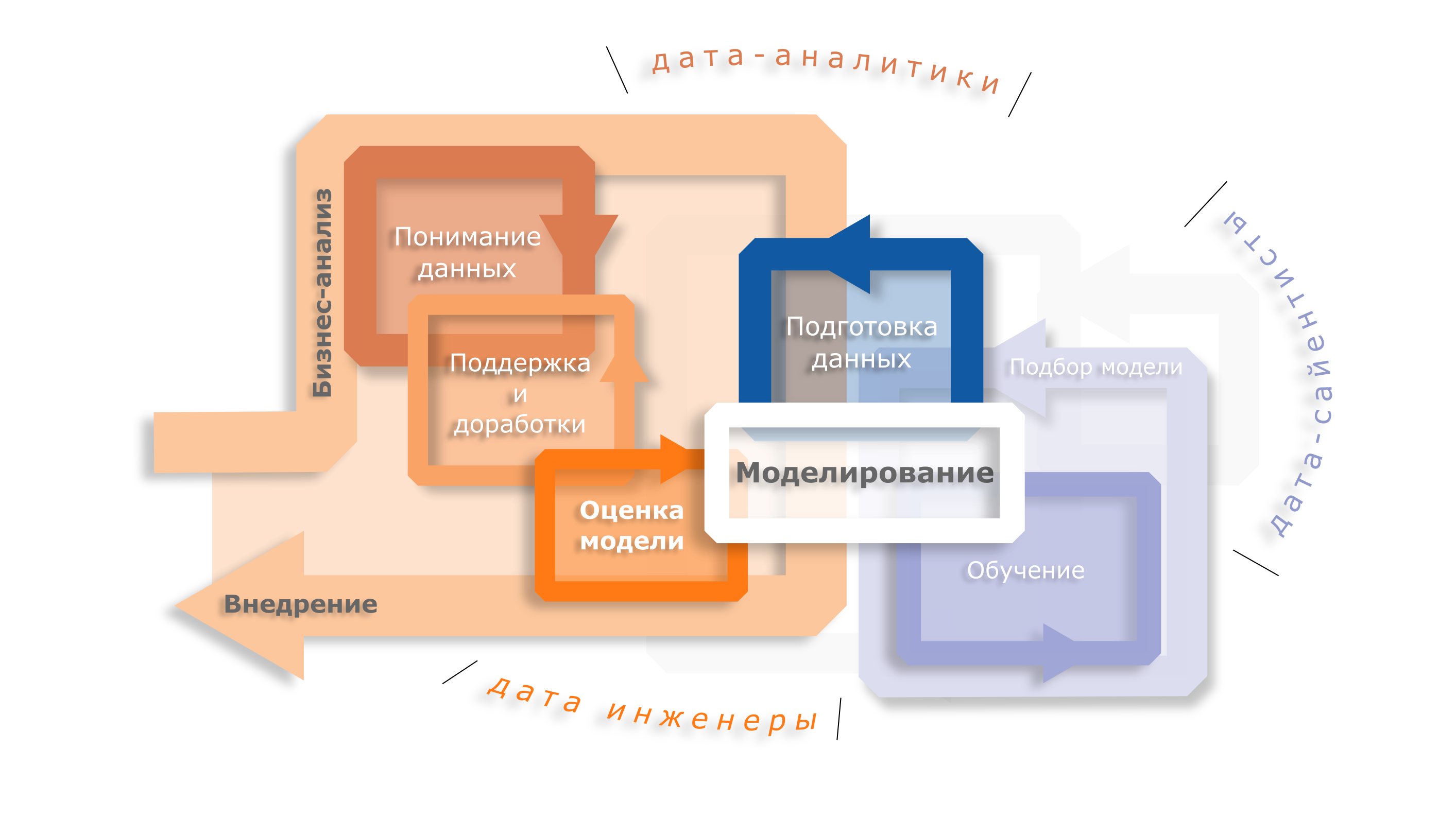
Основные понятия данного этапа – бизнес-ценность и сервисы. Наличие сформулированной и отраженной в техническом задании потребности заказчика является обязательным условием перехода к следующему этапу.
Мы не раз помогали нашим клиентам составить эффективный план внедрения технологий под конкретные прикладные задачи, начиная от выбора темы пилотного проекта, и заканчивая полномасштабным внедрением на предприятии, включая разработку внутренних стандартов качества и методологий разработки и бизнес-аналитики.
Поиск и понимание данных
Данных не бывает слишком много. Когда цели и задачи проекта согласованы и переданы в команду разработки, начинается этап сбора данных из любых источников. Самые ценные данные может предоставить только заказчик разработки: SQL/noSQL базы данных, веб серверы, логи, сетевые хранилища и репозитории. Нередко пользу можно извлечь и из внешних источников: публичных датасетов и уже опробованных алгоритмов анализа данных, сократив себе объем работы.
Качественному датасету нужна качественная разметка. Она требуется не во всех задачах, но, в идеале, каждый объект учебной выборки должен сопровождаться пометками о желаемом решении ИИ-алгоритма («таргетами»: класс изображения, стиль текста, время поломки детали...). Если у Вас много сырых данных, можно обратиться в службы разметки и привлечь фрилансеров через краудсорсинговые биржи, созданные крупнейшими русским компаниям.
Чтобы получить более устойчивую модель, аналитики могут «аугментировать» данные, то есть синтезировать новые объекты датасета из старых. Например, берем некоторую картинку из датасета и сохраняем ее же копию, но слегка повернутую или растянутую в любом направлении. Получается огромный датасет, на базе которого можно будет обучить по-настоящему помехоустойчивый алгоритм.
Выбор спектра данных, определение их нужного количества, предварительная обработка и фильтрация, заполнение пропусков – все это важнейшие этапы любого проекта на data science и ИИ. Участие внешнего эксперта часто позволяет «не замылить» глаз и провести эту работу качественно с учетом дальнейших совместных шагов. Более того, мы готовы помочь вам автоматизировать работу по сбору данных и сократить время данной рутины на следующих проектах.
Подготовка данных
Параллельно с этапом сбора данных идет подготовка и оценка полученного датасета. Часто это самая длительная и трудоемкая работа во всем проекте. Здесь аналитик постоянно следит за тем, набрали ли мы достаточно данных и нужно ли убирать из них прямые ошибки (измерения или сохранения данных), паразитные взаимосвязи (например, заложенные в данных предрассудки или утечки), выход за численные рамки, физические пределы или нарушение статистических гипотез… Данные с признаками ошибок можно отбросить, скорректировать, либо просто использовать, если в проекте допустимо сдвигать метрики качества данных.
Датасет будет готов, когда аналитик доведет его качество до желаемого с точки зрения таких метрик, как достоверность, точность, полнота, консистентность, единообразие и т.д.
На этом же этапе можно снабдить объекты новыми признаками. Библиотеки для работы с изображениями помогут подсчитать площадь объектов или гистограмму изображения, модули обработки звука помогут проанализировать частоты и фонемы, и так далее. Для синтеза признаков можно использовать и существующие «предобученные» нейросети – как из публичных источников, так и уже обученные на данном предприятии. Это хороший повод никогда не выбрасывать старые модели. Архивирование и контроль версий нужны как для моделей, так и для датасета на которой они были обучены.
Полученные на данном этапе данные можно по праву назвать «фундаментом проекта». Качественный датасет сам по себе обладает бизнес-ценностью, ведь на нем можно обучить множество моделей.
В ходе подготовки датасета аналитик пытается добиться понимания закономерностей, скрытых в данных. Структура модели на этом этапе еще не выбрана, к данным применимы любые гипотезы. Некоторые взаимосвязи позволяет найти разведочный (эксплоративный) анализ данных. Его целью будет:
- Выявление очевидных структур в данных
- Выбор наиболее важных и значимых переменных
- Обнаружение отклонений и аномалий
- Проверка основных гипотез
- Разработка начальных моделей
Работа по поиску закономерностей и взаимосвязей внутри датасета ведётся с помощью различных методов визуализации данных и статистического тестирования.
Именно на этом этапе данные начнут “раскрывать свои секреты” с помощью графиков, диаграмм и работы с гипотезами. Результат - выявление значимых/ключевых признаков и переменных.
Современные средства технических вычислений позволяют “переварить” данные с любых источников (приборы, базы данных, платы ввода-вывода, сеть Интернет и пр) и форматов, легко, применяя инженерные low code приложения, визуализировать, пред-обработать, проанализировать их и подготовить к дальнейшей применению. А самое важное, этот процесс может быть автоматизирован на будущее и занимать не так много времени. Наша компания уже обучила сотни инженеров применять подобные средства, а также передала компетенции в области автоматизации сбора различного типа данных в совершенно разных областях, сэкономив сотни часов, которые ушли бы на ознакомление со справкой и самостоятельное обучение технологии.
Моделирование и обучение
После создания датасета проект переходит в фазу машинного / глубокого обучения. Создание модели – сложный процесс, сопряженный с рядом трудностей, такими как:
- Выбор и модификация архитектуры решения
- деталей подготовки данных
- количества и состава слоев и т.д.
- Подбор деталей процесса оптимизации, например:
- архитектуры решения (функции потерь, метрик, дропаут, и т.д.)
- параметров оптимизатора (типа алгоритма, модификаций, скорость обучения и т.д.)
- Подбор основных метрик качества в зависимости от бизнес требований заказчика
Аналитикой данных должен заниматься дата-аналитик (DA), внедрением результатов – дата-инженер (DE), моделированием – дата-сайентист (DS). Порой все эти роли комбинируются. но в своей основе, профессия DS должна быть сосредоточена именно на создании инструментов и методов решения задачи ИИ... Это близко к научной деятельности, и такой работы не всегда очень много в проекте, гораздо больше времени уходит на анализ и инженерию данных.
В результате модель и данные сочетаются в обученный алгоритм, отвечающий формализованным на первом этапе бизнес-требованиям заказчика.
На этом все? О нет, это только половина пути. Впереди нам предстоит узнать, на сколько новая модель на самом деле будет полезна бизнесу: нас ждут валидация, внедрение и мониторинг.
Очень часто специалисты в области ИИ не являются специалистам в той прикладной области, в которой работает ваша компания или предприятие. И это естественно. Поэтому оптимальным сценарием для Вас может быть наращивание компетенций по data science и ИИ внутри своего коллектива. Это можно сделать, пригласив внешнего эксперта ИИ для передачи этих самых компетенций. Наша компания ставит перед собой именно такую задачу и с помощью наших экспертов Ваши инженеры научатся необходимым навыкам в data science, смогут синергично применять их с учетом своих знаний в прикладной области, и тогда архитектура их моделей и алгоритмов будет наиболее оптимальна.
Автоматическое обучение моделей
Если перед вами регрессия или классификация табличных данных (или другая сравнительно простая задача), то можно попробовать автоматический перебор моделей машинного обучения (AutoML).
На выходе вы получаете модель с наилучшими метриками. Этот метод пока не так хорошо работает для сложных задач вроде классификации сигналов или изображений, но всякий раз стоит попробовать. Среди перечня потенциально полезных задач в компании есть множество таких, на которые жаль тратить свое время. Решение таких задач по отдельности может не принести заметной экономии, но общий эффект от автоматизации их в своей массе будет достаточно или даже значительно существенный. Например, автоподсказка какого-нибудь поля в договоре или форме может сэкономить сотруднику несколько часов рабочего времени в месяц.
AutoML – неплохое решение для разных микро-задач. Оно позволяет извлечь прибыль из процессов, оптимизация которых прежними методами никогда бы не окупила затраченные усилия.
Не знаете, какие AutoML применения существуют? Обратитесь к нам, мы поделимся опытом в этой области и постараемся подобрать примеры сценариев, которые были бы полезны для решения именно ваших задач.
Оценка и валидация модели
Чтобы внедрить модель машинного/глубокого обучения в контур внешней системы, нужно убедиться в ее приемлемости в реальных задачах, то есть провести ее через валидацию.
Качественная модель должна не только удовлетворять метрикам точности (не слишком часто на "стандартных" данных), но также:
- не иметь предвзятости и ложных корреляций, то есть не пользоваться неадекватными зависимостями;
- иметь достаточный запас робастности, чтобы избежать катастрофических сбоев, вызванных “грязными” или “отравленными” данными;
- не иметь обходных путей (паразитных корреляций), специально заложенных разработчиками.
В распоряжении сотрудников, занимающихся валидацией, есть следующие методы:
- оценить качество модели на валидационном датасете, чтобы проверить, что модель правильно обучилась всему, чему ее учили;
- решить задачу с нуля собственными инструментами, например, автоматизированным перебором моделей;
- статистический анализ: запустить модель с видоизменённым датасетом или с заметным шумом на входе, чтобы выявить статистически значимые отклонения в ее поведении.
Валидация – очень важный этап управления качеством. А если моделей становится много, то валидация – ключевой шаг к серьезному менеджменту жизненного цикла моделей.
В мире очень распространена практика, что валидацией систем или алгоритмов занимается сотрудник или группа сотрудников, которая отделена от основный группы разработчиков для обеспечения нейтралитета и сохранения “свежего взгляда” на систему. В ходе подготовки этапа валидации очень важны методологические знания об организации данного процесса, а также знание возможностей современных инструментов, которые позволяют автоматизировать тестирование и моделирование систем. «Инженерный DevOps» (EngOps) – управленческие практики построения процессов и инфраструктуры командной разработки сложных технических систем, повышающие прозрачность, автоматизацию вспомогательных рутин обеспечения качества и связности проекта. Специалисты ЦИТМ Экспонента имеют богатый опыт внедрения лучших практик инженерного DevOps и готовы пройти эти этапы вместе с Вашей командой.
Внедрение
После успешного внедрения модель наконец приобретает бизнес-ценность. Перед этим иногда разумно отправить модель на этап пилотирования: пилотная эксплуатация позволяет собрать новые данные в контролируемом окружении, а по итогам снова провести модель через валидацию. Это актуально для критических моделей, сбои в которых могут принести организации заметные финансовые, репутационные или другие потери.
Когда приходит время, команда разработки приступает к следующим шагам:
- осуществляет развертывание модели (деплой) в предпродакшн/продакшн среде,
- осуществляет контроль работоспособности и оптимальности работы модели на выделенных вычислительных ресурсах заказчика
- настраивает рутинные задачи для сбора данных во время эксплуатации и автоматической проверки внедренной модели.
Как мы уже писали, специалисты Экспоненты помогут разобраться в релевантных задачах и понять, где методы ИИ применимы и насколько будут полезны. Мы определим те шаги по развитию ИИ, реализация которых наиболее оправдана на Вашем предприятии, убережем от тупиковых направлений, когда ИИ методы не принесут существенного эффекта. Мы подскажем, каким программными и аппаратными средствами наиболее эффективно будет внедрить ту или иную практику и методологию data science в ваш непосредственный жизненный цикл проекта или разрабатываемых изделий.
Мониторинг
Чтобы в Вашей организации заработал полноценный MLOps, к текущим процессам нужно добавить мониторинг моделей в их рабочем окружении.
Работающая модель постепенно утрачивают качество, поскольку:
- тренировочные данные устаревают,
- в рабочем окружении возникают новые зависимости,
- аналитики находят в моделях ошибки,
- заинтересованные лица могут находить способы обмануть модель…
Постановка моделей на мониторинг – это прежде всего настройка автоматизированного отслеживания важных метрик. Так можно обнаружить дрейф данных, смещение распределений входа-выхода, рост аппаратных метрик (например, что модель начинает работать медленнее) и, в итоге, вовремя заменить устаревшую модель на актуальную.
Вместе мы можем определить, какие метрики являются наиболее важным, какими методами будет проводится мониторинг моделей, когда стоит внедрять новую версию системы и так далее. Успешная реализация и автоматизация на данном этапе позволяет заложить уверенность команды в применении методов data science и перенести достижения на дальнейшие проекты Вашего предприятия, а значит сэкономить средства и время, выиграв их для разработки новых технических и информационных систем.
Заключение
Если вам нужно быстро реализовать data-проект и нет времени заниматься исследованиями, то вы на верном пути. Добавленную стоимость создает не усложнение моделей, а работа с данными. Причём прибыль принесут только те модели, которые можно внедрить быстро, и на фундаменте уже имеющихся данных. Иными словами – лучше вложить рубль в разметку датасета, а не в тюнинг архитектуры нейросети. И это делает анализ данных настоящей золотой жилой для бизнеса. Можно использовать современный фреймворк и стандартные решения, но ничто не заменит свежих, релевантных данных.
Мы воплощаем лучшие практики и предоставляем оборудование, чтобы Вы могли сосредоточиться на основных бизнес-задачах: принятии решений, проведении переговоров и воплощении новых проектов. Доверьте нам работу с данными, и очень скоро Вы увидите новые возможности в действии.
Проверка концепции AI
Проблематика
Возможно ли на основе имеющихся данных построить предсказательную модель или можно ли в принципе собрать данные требуемые для целевой модели?
Действительно ли для решаемой задачи нужно применять методы глубокого обучения, или можно обойтись менее затратными вычислительными методами, такими как линейные модели, машинное обучение и т.д.?
Исследование
Анализ данных и выявление значимых паттернов, особенно в условиях, когда данные не имеют заранее заданную структуру, - это творческий процесс, требующий компетенций в работе с данными и алгоритмами, а также удобного инструментария и накопленной большой библиотеки методов и алгоритмов для быстрой проверки идей. Также требуется опыт управления временем исследования, поскольку все возможные комбинации перебрать невозможно, а ошибки в выборе исследуемых гипотез стоят дорого: много трудозатрат, вычислительных ресурсов, упущенные возможности и время. При рассмотрении конкретных задач мы отсекаем некоторые гипотезы экспертно, некоторые гипотезы исследуем частично в ограниченное время, а часть глубже. В зависимости от достижения некоторого порога значимости влияния данных на переменную отклика мы делаем заключение о возможной эффективности тех или иных методов искуственного интеллекта (ИИ).
Результат
Реалистичный план ИИ проекта или техническое задание, в которое входят:
- организационная схема решения задачи (по возможности - прототип в MATLAB)
- обоснованные требования к качеству и количеству данных, их достаточности
- оптимальная методика сбора и предобработки данных (в некоторых случаях - приложение автоматизирующее сбор и разметку данных)
- выбранные архитектуры нейронных сетей или более простых алгоритмов
- схема развертывания или портирования алгоритмов, соответствующая выбранным сетям (например, развертывание на корпоративном сервере, на мобильном телефоне, встроенных платформах основанных на GPU, FPGA, MCU, CPU)
- рекомендации по обучению и дообучению систем.
- Deep Learning Toolbox
- Statistics and Machine Learning Toolbox
- Parallel Computing Toolbox
- Text Analytics Toolbox
- Predictive Maintenance Toolbox
- Audio Toolbox
- Database Toolbox
- Image Processing Toolbox
- Computer Vision Toolbox
- Signal Processing Toolbox
- Wavelet Toolbox
- Fuzzy Logic Toolbox
- System Identification Toolbox
- OPC Toolbox
- Data Acquisition Toolbox
- Image Acquisition Toolbox
- MATLAB для профессионалов (MLBE)
- Обработка и визуализации данных в MATLAB (MLVI)
- Машинное обучение в MATLAB (MLML)
- Глубокое обучение в MATLAB (MLDL)
- Статистический анализ в MATLAB (MLST)
- Обработка изображений в MATLAB (MLIP)
- Разработка систем компьютерного зрения в MATLAB (MLCV)
- Обработка сигналов в MATLAB (MLSG)
- Предобработка и извлечение свойств сигнала с MATLAB (MLSP)