Машинное обучение
Технологии машинного обучения направлены на создание алгоритмов, которые делают то, что естественно для людей – учатся, исходя из опыта. Алгоритмы машинного обучения используют математические методы, чтобы «учиться» получать информацию напрямую из данных без использования каких-то предопределенных уравнений или моделей. При этом чем больше данных используется для обучения, тем более точные получаются модели.
В машинном обучении существует две разные техники:
- Обучение с учителем, когда на имеющихся входных и соответствующих им выходных данных тренируют модель машинного обучения. Она в свою очередь учится эти данные сопоставлять и начинает предсказывать выход для новых входных данных.
- Обучение без учителя, когда модель тренируют только на входных данных, а она учится находить в них скрытые взаимосвязи или группировать.
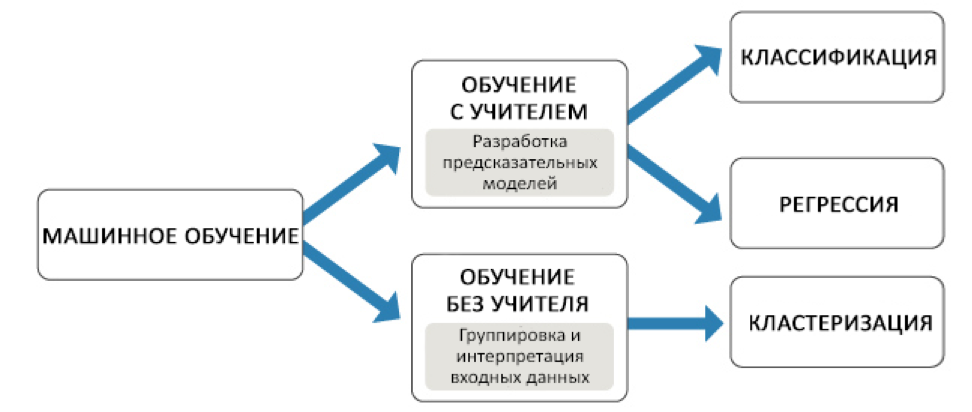
Обучение с учителем также в свою очередь разделяется на две техники:
- Классификация – когда модель должна предсказать какую-то категорию из ограниченного набора. Например, на фото изображен кот или собака, голос на записи скорее является мужским, женским или детским, и т.д. Методы классификации часто применяются для распознавания образов или речи, скоринга, предсказания отказов.
- Регрессия – когда на выходе модели получается непрерывная величина. Например, изменение температуры или колебания потребления электроэнергии. Такие методы часто применяются при прогнозировании погоды, в энергетике, алгоритмическом трейдинге.
Самой распространённой техникой машинного обучения без учителя является кластеризация, когда на основе имеющихся данных, мы разбиваем объекты на какие-то группы, исходя из скрытых взаимосвязей, которые человек может не видеть или не понимать. Часто используется как метод исследования данных (data mining).
Выбор метода
В рамках приведенных техник существует больше количество различных методов машинного обучения, начиная от простых и интуитивных, заканчивая настолько сложными, что разбираться в их математике исследователю не имеет смысла (нейросети).
Важно понимать, что среди десятков разных методов не существует тех, которые наилучшим образом подходят для всех задач: простые модели могут работать недостаточно точно, а сложные – быть очень тяжелыми и сложными в реализации. Выбор метода под конкретную задачу почти всегда осуществляется методом проб и ошибок. К счастью, MATLAB позволяет очень быстро пробовать разные методы и помогает выбирать наиболее подходящие.
Рабочий процесс
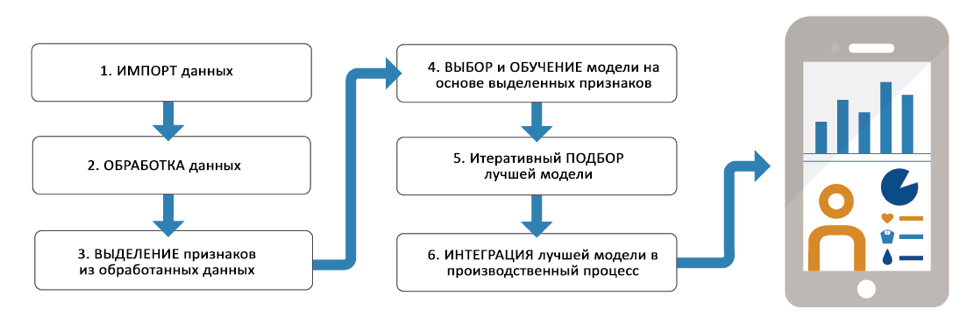
Импорт данных
Рабочий процесс начинается с получения данных. Данные могут храниться в файлах, в базах данных, в интернете. MATLAB позволяет не только получать данные из указанных источников, но и собирать напрямую с оборудования, если это сигналы, например.
Обработка данных
Собранные данные нужно обработать, чтобы повысить их качество. Например, заменить пропуски, удалить выбросы, отфильтровать шумы. MATLAB имеет готовые функции для решения подобных задач, которые расширяются специализированными тулбоксами.
Выделение признаков
Когда данные подготовлены, нужно внимательно их изучить и выбрать из всего многообразия именно те данные, которые должны или теоретически могут повлиять на результат предсказания. Например, если мы распознаем пол человека по фото, то цвет глаз человека вряд ли поможет определить его пол. Поэтому этот признак имеет смысл исключить из процесса обучения, что позволит сделать более адекватную и менее перегруженную модель. Варьируя набор признаков, мы можем получать модели разного качества, поэтому это один из самых важных этапов.
MATLAB предлагает набор техник машинного обучения по выделению признаков из данных.
Выбор и обучение модели
Дальше начинается во многом творческий процесс подбора нужной модели из всего многообразия. Мы меняем типы моделей, меняем их настройки и обучаем, пока не получим модель приемлемой точности и сложности. Конечно, не обязательно начинать с нуля. Изучив предметную область, мы можем сразу начинать подбор с наиболее успешных кандидатов. К примеру, для задач распознавания часто имеет смысл начинать сразу с глубоких нейросетей.
Подбор лучшей модели
MATLAB позволяет сильно оптимизировать процесс подбора и обучения моделей, доведя его буквально до автоматизации, а встроенные в документацию примеры позволят изначально выбрать самых перспективных кандидатов.
Развертывание модели
После получения итоговой модели, её нужно развернуть, чтобы модель начала приносить пользу. Для переноса моделей машинного обучения с компьютера разработчика в производство MATLAB предлагает несколько подходов и инструментов.
Например, MATLAB Compiler позволит скомпилировать модель в независимое приложение, которое можно развернуть на сервере предприятия, а MATLAB Coder – сгенерировать C/C++, HDL или GPU код для запуска алгоритмов на встраиваемых системах и автономных устройствах.
Отдельный инструмент MATLAB Production Server позволит развернуть в сети вашего предприятия или в облаке полноценную аналитическую систему на основе алгоритмов MATLAB.
Дополнительно
MATLAB позволяет обучать модели на больших данных (Big Data) для получения более точных моделей, а также использовать параллельные вычисления (на многоядерных процессорах, кластерах и GPU), чтобы существенно ускорять процесс получения моделей.
Реализована работа с этими технологиями максимально бесшовно и удобно для разработчиков, которые избавлены от необходимости вникать в тонкости работы с большими данными и распараллеливанием алгоритмов и могут полностью посвятить свое время непосредственно процессу обучения.